When setting out to build large data driven pages in Node.js there are a lot of things to consider, such as scaling and maintenance. In this article I will break down the thought process utilized on a Fortune 40 eCommerce website.
The first step should be to decide how many Node applications will serve the desired pages. My ideal solution would be a single application focuses on rendering a set of similar pages. Let’s take for example product browsing, we could break it down into product search and listing as one application, and product details into another. This would allow a team for each application to develop with minimal conflict and scale each area of the site separately as needed.
The second step would be to identify what type of data will be used for display, and how to best cache the results. For the sake of this design I will refer to Edge Server Includes (ESIs) much like Akamai offers; these will allow you to cache HTML fragments separate of the main page. You’ll also want to cache the raw data from your services somewhere, I’d suggest Redis or Memcached. Doing so will prevent your node applications from hitting your services more than necessary, increasing response time.
Lets break down a Product Detail page from a major retailer.
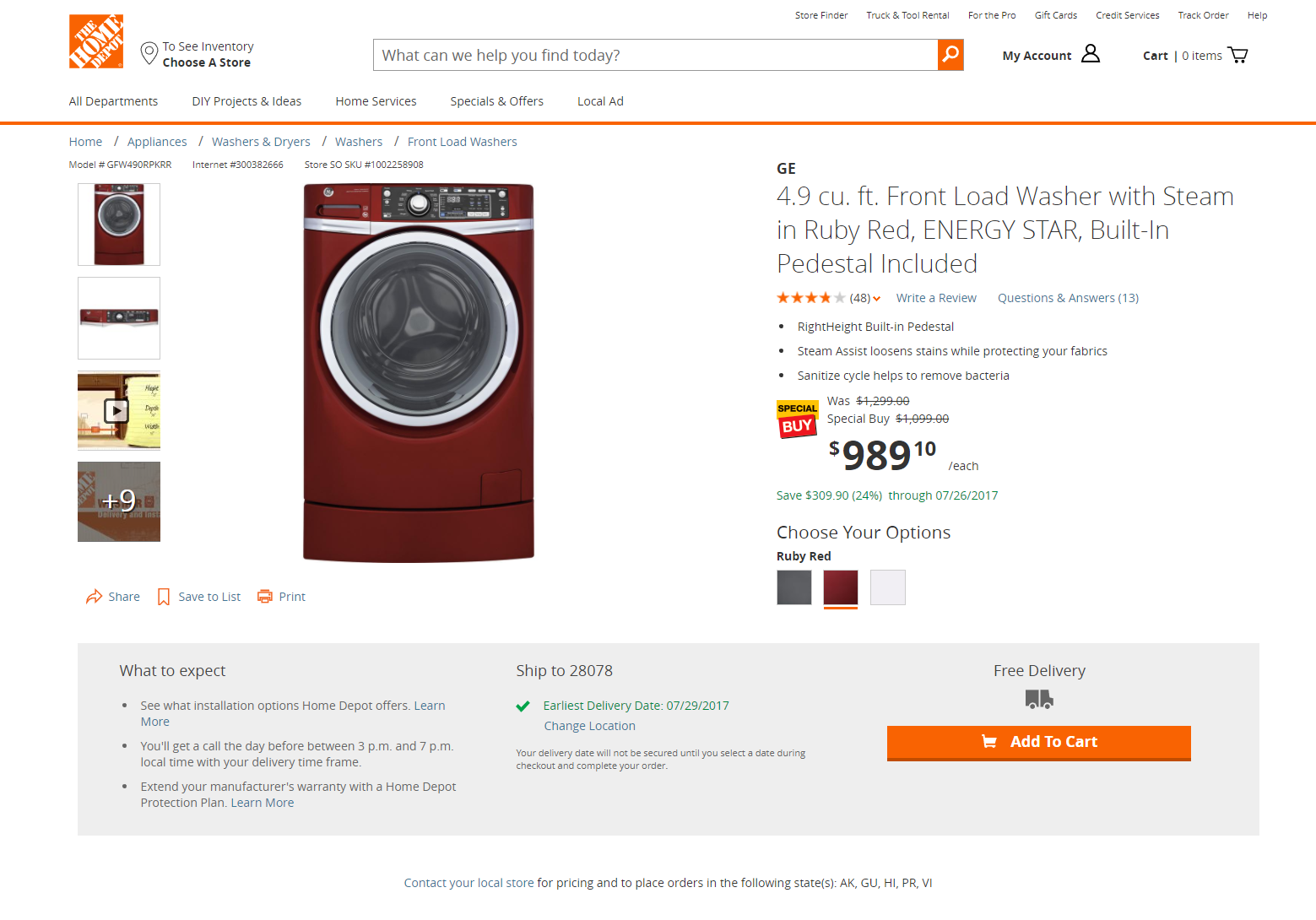
Starting with the Header and Footer of the page, these should be ESI’s that are cached for a long duration and re-used globally across the site, usually not unique to any one page.

Next we have the product pricing area, often this data is short lived due to price changes throughout the day or unique to a retail store location. This is another opportunity for ESIs, however set to a shorter cache duration such as 15 minutes.

Following the pricing area we have the product availability section, the data in this area impacts the customers ability to add the product to their cart, as well as message the customer what options they have for fulfillment. Again, this data is more time sensitive and should be cached for a short period.
Now when we look at the general product information across the rest of the page, its not likely to be time sensitive. This is where we can cache the rest of the page for a longer period of time, such as a day or whatever cadence product content would be updated. There are some areas of the page that would could likely defer from initial page load, such as Customer Reviews content.
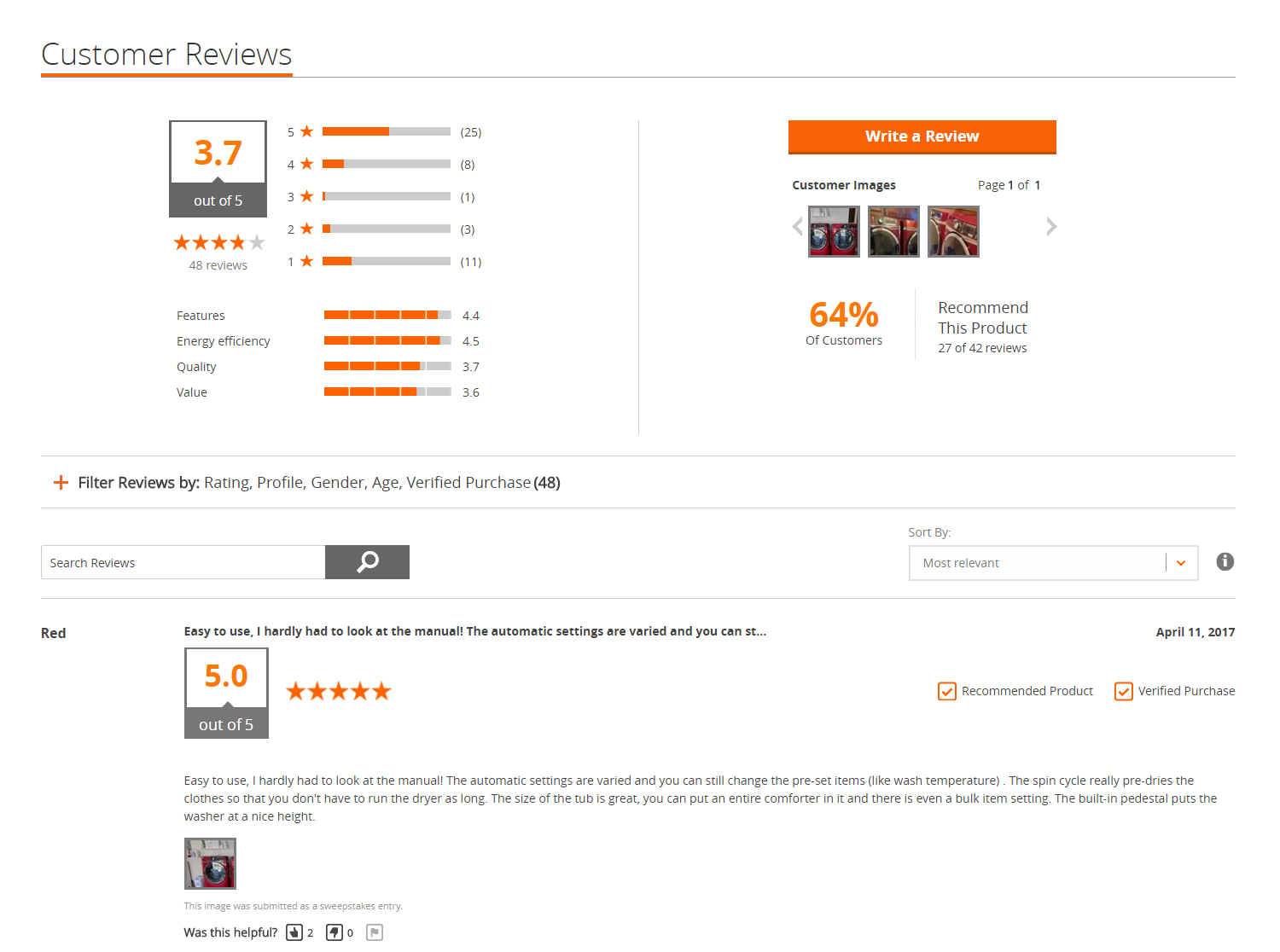
This content is likely updated more frequently, and since its further down the page could be hidden behind a call to action like an accordion. That would allow you to make an asynchronous call on the front end to get the content when the user interacts, otherwise never loading it if the user doesn’t. This would save on initial page size and loading time.
Another area on the page is recommended products based on the current product, this could be treated in a similar fashion, perhaps even displaying the content on page scroll instead of a call to action.
While I covered a few examples of content on the page that could be fragmented or deferred after initial page load, there may be lots of other opportunities based on the full breadth of content displayed on any given products page.
Designing API call flows
After solving for the content caching, the next area to focus on would be the flow of API calls each fragment and page consumes. Take for instance the detail page, there’s likely calls for product information, pricing, availability, review content, and product recommendations. While these calls would traditionally be made one after the other in a Java platform, Node’s best feature is the asynchronous event driven model. This allows you to call all the services in parallel and begin rendering the page as soon as all of them completed, rather than waiting on each call to make the next. Combined with a micro-services model this would allow for the fastest possible page response times, as well as flexibility to scale where needed.
I hope this gives some insight into the thought process of designing an architecture with Node to serve millions of visitors a day.
article originally posted on Medium